
Китайські моделі штучного інтелекту дешевші та адаптивніші, ніж провідні американські платформи, і дослідження показують, що зараз вони майже такі ж ефективні. Як це сталося?
Китайські компанії зі штучного інтелекту не можуть зрівнятися з фінансовою потужністю своїх американських конкурентів, а уряд США позбавив їх найсучасніших чіпів для навчання їхніх моделей штучного інтелекту. Проте Китай зазіхає на лідерство США в цій галузі.
Китайські розробники, такі як DeepSeek та Alibaba Group Holding Ltd., зосередилися на розробці систем, які функціонують майже на рівні найпродуктивніших моделей штучного інтелекту, не потребуючи найпотужнішого обладнання. Китай також робить ставку на програмне забезпечення для штучного інтелекту «відкритого типу», де внутрішні параметри доступні розробникам для обміну, вивчення та налаштування, як спосіб сприяння швидкому впровадженню штучного інтелекту в національній економіці. Все це кидає виклик домінуючій бізнес-моделі США, яка базується на інвестуванні мільярдів і змушенні користувачів платити величезні суми за найпотужнішу, запатентовану технологію штучного інтелекту.
Ось що потрібно знати про китайський штучний інтелект і яку загрозу він становить для OpenAI Inc., Anthropic та інших американських гігантів.
Ефективність
Експортний контроль, запроваджений Вашингтоном, обмежує доступ Китаю до американських чіпів, які приблизно на 20% швидші та споживають до 30% менше енергії, ніж їхні китайські конкуренти, оскільки вони розміщують більше транзисторів на кожному шарі кремнію. Китайська технологічна спільнота прагне подолати цю перешкоду, розробляючи програмне забезпечення для штучного інтелекту, яке є більш «стислим». Це означає, що для досягнення результатів, порівнянних з результатами найкращих американських моделей штучного інтелекту, потрібно менше кроків обчислення.
Один зі способів досягнення цього – використання техніки, відомої як змішання експертів. Коли користувач запитує китайського чат-бота, такого як DeepSeek або Qwen від Alibaba, моделі не потрібно мобілізувати всю свою «нейронну мережу» для генерації відповіді (процес, відомий як висновок). Натомість вона активує спеціалізовані підмережі, відомі як експерти, які залучають лише частину доступної обчислювальної потужності програмного забезпечення.
Моделі американських лабораторій, таких як OpenAI та Anthropic, часто мають перевагу, коли йдеться про величезний обсяг інформації, який вони можуть обробити за одну взаємодію, та складність їхніх реакцій. Але для досягнення цього вони активують набагато більше доступних «нейронів» моделі та тим самим споживають набагато більше обчислювальної потужності. Згідно з даними про продуктивність, опублікованими компанією, в останній моделі DeepSeek , V4-Pro, менше 3% її параметрів фактично працюють у будь-який момент часу.
Наближення продуктивності
Китайські розробники штучного інтелекту скоротили розрив у продуктивності з американськими конкурентами
Глобальні технологічні акції впали наприкінці січня 2025 року після того, як DeepSeek продемонструвала нову модель R1, яка забезпечувала порівнянну продуктивність з американськими чат-ботами на базі штучного інтелекту, при, здавалося б, частці вартості їхньої розробки. Сьогодні, хоча OpenAI, Anthropic та Google все ще пропонують найпродуктивніші у світі інструменти штучного інтелекту, DeepSeek та менший китайський конкурент Moonshot тепер входять до топ-12, згідно з рейтингом моделей великих мов LiveBench. І вони набагато дешевші: GPT-5.2 від OpenAI коштував 14 доларів за мільйон вихідних токенів (одиниць даних, оброблених моделями штучного інтелекту у відповідь на запит користувача) станом на лютий — приблизно в 33 рази більше, ніж V3.2-Exp від DeepSeek, на рівні 42 центів США за мільйон токенів.
Anthropic звинуватила DeepSeek, Moonshot та ще одну китайську лабораторію штучного інтелекту MiniMax у «атаках дистиляції промислового масштабу» — незаконному вилученні можливостей з її власної моделі Claude з використанням 24 000 шахрайських облікових записів для отримання переваги. Відтоді Anthropic, OpenAI та Google співпрацюють, щоб спробувати викорінити таку практику. DeepSeek, Moonshot та MiniMax не відповіли на електронні листи з проханням прокоментувати ситуацію.
Відкрита архітектура
Нове покоління інструментів штучного інтелекту працює, використовуючи всіляку інформацію, записану людьми, для виявлення закономірностей у даних та запису найпоширеніших зв’язків між складами, словами, звуками чи пікселями. На основі цього вони створюють величезну нейронну мережу, яка може розбити компоненти письмової підказки та надсилати найімовірнішу корисну відповідь на основі навчальних даних.
Провідні американські платформи не публікують параметри моделей штучного інтелекту, таких як ChatGPT, Claude або Gemini. Тому сторонні розробники штучного інтелекту або не можуть їх відтворити, або їм доводиться платити за цей привілей. Хоча китайські компанії, що займаються штучним інтелектом, можуть бути такими ж секретними щодо того, які дані вони використовували для навчання своїх систем, багато хто з них зробив параметри, призначені у вигляді числових значень та налаштовані під час навчання своїх моделей штучного інтелекту (відомих як ваги), доступними для завантаження. Це дозволяє університетам, стартапам та невеликим технологічним фірмам використовувати та коригувати моделі, щоб вони могли краще виконувати певні завдання без додаткових витрат.
Такий підхід ефективно залучає національні дослідження та розробки в галузі штучного інтелекту за допомогою краудсорсингу, знижуючи витрати на підтримку та оновлення моделей. А додаткова гнучкість моделі спрощує впровадження штучного інтелекту в широкому спектрі галузей.
R1 швидко набула популярності після того, як DeepSeek опублікував вагові коефіцієнти моделі. Розробники створили версії R1 для завдань, пов’язаних з фінансами, медициною та китайською мовою. Сімейство моделей штучного інтелекту Qwen від Alibaba до січня перевищило 1 мільярд завантажень, що зробило його найпоширенішим сімейством моделей штучного інтелекту з відкритим кодом, випередивши платформу Llama від Meta Platforms Inc. Марка Цукерберга . Alibaba заявила, що Qwen породила понад 200 000 похідних моделей штучного інтелекту по всьому світу.
Регіональні уряди Китаю фінансують моделі відкритої ваги та заохочують появу спільнот штучного інтелекту, які розміщують тисячі моделей та наборів даних як спільні активи, що можуть використовуватись на благо місцевих компаній. Уряд Китаю розглядає цей підхід, спрямований на розширення впровадження технології в економіці, навіть якщо це зменшує прибутки окремих технологічних фірм, як інструмент м’якої сили. Китай є активним спонсором таких ініціатив, як Глобальний план дій щодо управління штучним інтелектом від липня 2025 року, який спрямований на те, щоб зробити моделі штучного інтелекту доступнішими для розробників програмного забезпечення в країнах з низьким рівнем доходу.
Енергія
Оскільки навчання та експлуатація послуг штучного інтелекту споживають величезну кількість електроенергії, їх швидке впровадження створює навантаження на енергетичні мережі по всьому світу. У деяких країнах встановлення нових електростанцій, сонячних та вітрових електростанцій, ліній електропередач, підстанцій та трансформаторів, необхідних для роботи зі зростаючим попитом, є справжнім випробуванням.
У Китаї це виявляється меншою проблемою, адже він нарощує потужності для виробництва електроенергії швидше, ніж інші країни. У деяких регіонах Китаю, таких як Внутрішня Монголія, велика кількість дешевої електроенергії з відновлюваних джерел призвела до будівництва сотень центрів обробки даних, призначених для навчання моделей штучного інтелекту.
Уряд Китаю обмежує рахунки за електроенергію для своїх компаній, що займаються штучним інтелектом, щоб надати їм конкурентну перевагу над іноземними конкурентами. Держава субсидує половину витрат на електроенергію деяких найбільших центрів обробки даних країни, якщо вони використовують виключно китайські чіпи.
Промисловість
У більшій частині світу найбільш інтенсивне впровадження штучного інтелекту відбувається у сфері бізнес-послуг: автоматизація відносин з клієнтами, прискорення бізнес-процесів та підвищення продуктивності в таких секторах, як фінанси, юриспруденція та охорона здоров’я. Державний підхід Китаю робить акцент на підвищенні національної продуктивності шляхом впровадження штучного інтелекту в торгівлю, виробництво та логістику.
Можливо, це не дивно: економіка США значною мірою базується на послугах. Китай є домінуючим у світі виробником промислових товарів, включаючи електромобілі та інші низьковуглецеві технології, потужним гравцем електронної комерції та лідером у сфері робототехніки. За даними Міжнародної федерації робототехніки, Китай встановив понад половину нових промислових роботів у світі за останні роки, оскільки китайські виробники автоматизували перевірку, складання та логістику. Уряд чітко дав зрозуміти, що його метою є не створення найбільших і найбагатших компаній зі штучним інтелектом, а використання штучного інтелекту для отримання технологічної переваги для прискорення економічного розвитку.
Американські компанії та академічні установи є лідерами у фундаментальній, довгостроковій науковій роботі, спрямованій на розвиток фундаментальних технологій, що лежать в основі штучного інтелекту. Китайська спільнота розробників штучного інтелекту більше зосереджена на накопиченні величезних наборів даних з розгорнутого штучного інтелекту, які можна використовувати для покращення моделей. Автовиробник BYD впровадив штучний інтелект у свої лінії складання електромобілів, щоб скоротити тривалість циклу та зменшити кількість відходів матеріалів. Було задокументовано зниження кількості несправностей акумуляторів на 40% та покращення терміну служби акумуляторів на 20%, що компанія пояснює забезпеченням якості за допомогою штучного інтелекту.
Apple Inc. Китайський партнер зі складання iPhone, компанія Foxconn , впровадила комп’ютерний зір на основі штучного інтелекту для виявлення дефектів та оптимізації використання енергії на виробничих лініях. За її словами, це призвело до двозначного відсоткового скорочення споживання енергії на деяких об’єктах, тоді як автоматизовані перевірки якості, що проводяться за допомогою штучного інтелекту, знизили рівень браку . Системи штучного інтелекту гіганта електронної комерції Alibaba тепер обробляють більшість рутинного обслуговування клієнтів.
Уряд заохочує та навіть фінансує впровадження роботів на базі штучного інтелекту у виробничі, логістичні та сервісні завдання як спосіб подолання зростаючої нестачі робочої сили через скорочення населення працездатного віку. Чиновники в Пекіні діють обережно, враховуючи ризик того, що раптовий, повний перехід до автоматизації може призвести до масових звільнень та спричинити хвилю соціальних заворушень.
Бліц-дослідження штучного інтелекту в Китаї.
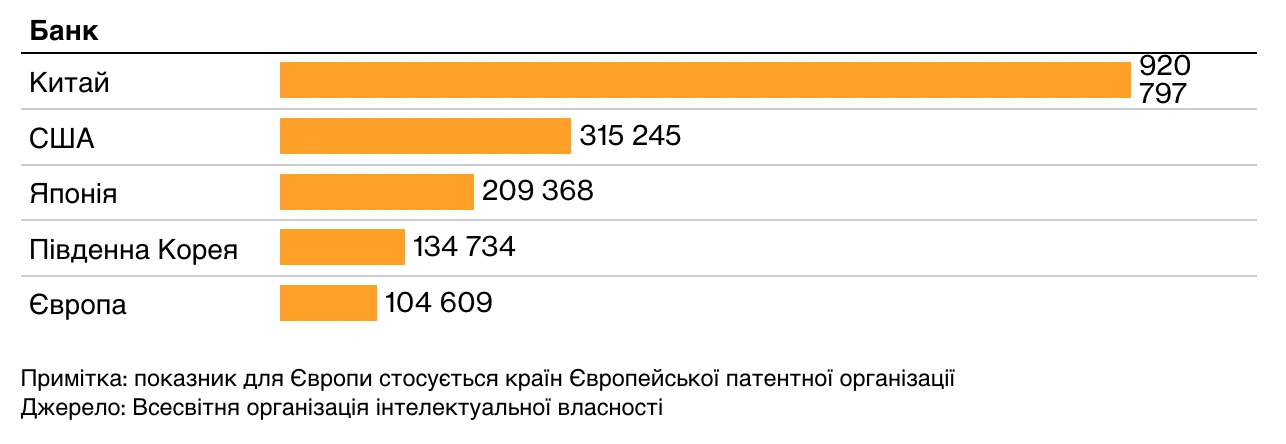
Кількість патентів, виданих у 2023 році
Національна стратегія
Навіть якби китайські технологічні підприємці хотіли приєднатися до гонки озброєнь у сфері обчислювальної потужності, яку проводять американські гіганти штучного інтелекту в пошуках величезних прибутків, немає жодної певності, що вони змогли б це зробити. Президент Китаю Сі Цзіньпін вже чітко заявив про своє несхвалення показного багатства, коли він придушив безтурботних мільярдерів країни з 2020 по 2023 рік. Він хоче, щоб капіталісти країни служили головній меті Комуністичної партії Китаю — стабільному економічному зростанню, що створює робочі місця.
Натомість уряд Сі створює національну екосистему для забезпечення стартапів у сфері штучного інтелекту науковими талантами, дешевим капіталом та комерційними можливостями. План розвитку штучного інтелекту нового покоління 2017 року узгоджує стимули між науковими установами та приватним сектором. Університети стимулюватимуть дослідження, а компанії комерціалізуватимуть свої прориви.
Найновіша державна ініціатива у сфері штучного інтелекту, запущена у 2025 році, AI Plus, спрямована на впровадження цієї технології в економіку та суспільство. Школярі початкової школи вчаться програмувати та створювати моделі штучного інтелекту. Місцеві органи влади створили субсидовані парки штучного інтелекту, а фірми отримують капітал, легкий доступ до величезної кількості даних для навчання моделей та гарантовані можливості закупівель. Кілька китайських стартапів у сфері штучного інтелекту були засновані професорами або випускниками елітних університетів після наукових проривів, а потім швидко введені в орбіту уряду. Розробник штучного інтелекту Knowledge Atlas Technology JSC Ltd. , або Zhipu AI, був заснований професорами Цінхуа Тан Цзе та Лі Цзюаньцзи у 2019 році та був заохочений до узгодження з національними цілями. Він забезпечив державних клієнтів та підтримку з боку державних фондів, таких як Пекінський фонд розвитку наукових міст Чжунгуаньцунь та регіональний уряд Ченду, а також скористався державними обчислювальними ресурсами та іншою політикою, що сприяє вітчизняним лідерам у сфері штучного інтелекту.
Вся ця державна підтримка змусила китайські компанії зі штучним інтелектом дотримуватися національних вимог, тому широкомасштабне впровадження цієї технології має перевагу над прибутками, згідно зі звітом Bloomberg Intelligence. опубліковано в грудні.
Приватні капітальні витрати на штучний інтелект
У Китаї бум штучного інтелекту здебільшого тягнуть за собою державні кошти.
Розширення за кордон
Уряд у Пекіні розглядає китайські моделі відкритої ваги, які можна впроваджувати в різні галузі промисловості, як національний актив, подібний до доріг, енергомереж чи телекомунікаційних мереж. Цей актив можна експортувати в інші країни, щоб сприяти залежності від китайських технологій.
Китайські та американські платформи штучного інтелекту конкурують у регіонах Південно-Східної Азії, Близького Сходу та Африки, де можливість доступу китайських організацій до урядових, корпоративних або персональних даних викликає менше занепокоєння, ніж у західних країнах.
Китайські технологічні гіганти Alibaba, Huawei Technologies Co. та Tencent Holdings Ltd. шукають клієнтів для власних хмарних платформ на деяких із цих швидкозростаючих ринків. Їхній план полягає в тому, щоб підірвати ціни американських конкурентів, пропонуючи клієнту все необхідне для початку використання китайського штучного інтелекту: саму платформу, таку як Qwen або DeepSeek, недорогі хмарні обчислення на базі Китаю, підключення до Інтернету та необхідне обладнання. Вони адаптували китайські моделі штучного інтелекту для роботи з місцевими мовами та дотримання національних правил. А уряд Китаю прагне полегшити їм цей шлях, надаючи фінансування багатьом із цих країн у рамках своєї ініціативи «Один пояс, один шлях» та інших програм.
Схоже, що цей підхід працює: за даними торгової площадки моделей штучного інтелекту OpenRouter, китайські моделі генеративного штучного інтелекту становили близько 15% світового ринку у листопаді 2025 року, порівняно з приблизно 1% роком раніше.
Чи є загроза для американських гігантів ШІ?
Наразі доступ великих китайських гравців до ринків США та Європи досить обмежений. Правила та норми, пов’язані з конфіденційністю даних та національною безпекою, означають, що клієнтам там, особливо державним установам та великим корпораціям, не рекомендується використовувати китайські хмарні обчислювальні сервіси.
Це не завадило великим американським хмарним постачальникам, таким як Microsoft Corp. та Amazon.com Inc., пропонувати своїм клієнтам китайські моделі штучного інтелекту та виконувати процес логічного висновку в центрах обробки даних за межами Китаю. Китайські платформи пропонуються як більш гнучка та адаптивна альтернатива американським моделям завдяки їхньому підходу, заснованому на відкритості. А оскільки вони, як правило, використовують менше обчислювальної потужності для реагування на запити користувачів, вони можуть бути набагато дешевшими.
Як китайські, так і американські компанії, що займаються штучним інтелектом, витрачають значні кошти на обчислювальну потужність, необхідну для роботи своїх платформ. Вони купують цю потужність для обробки даних як послугу у хмарних операторів, таких як Alibaba, Google, AWS або Microsoft. Величезні інвестиції в інфраструктуру штучного інтелекту базуються на очікуванні, що ці платформи поступово стануть настільки незамінними для робочого життя, що компанії зможуть значно збільшити плату, яку вони стягують з користувачів. Наразі ніхто не може з упевненістю сказати, коли, або навіть чи взагалі, ці доходи почнуть покривати всі витрати.
Це стосується як китайських компаній зі штучного інтелекту, таких як Minimax, яка витрачає величезні кошти на оплату обчислювальних потужностей Alibaba, так і OpenAI, Anthropic та інших американських гравців з великими витратами. Цього року Alibaba випустила кілька закритих, власних платформ штучного інтелекту поряд зі своїми відкритими моделями, що може свідчити про те, що китайські гравці також відчувають тиск щодо підвищення прибутковості своїх інвестицій у штучний інтелект.
Інвесторів в американський штучний інтелект турбує те, що нижча вартість та покращення продуктивності китайських моделей ускладнять для американських гігантів заявити, що їхні послуги виправдовують преміальні ціни, а також те, що значна кількість користувачів на західних ринках відкине будь-які побоювання щодо безпеки даних та оберуть китайські альтернативи.
«Країни-союзники США не використовуватимуть DeepSeek жодним офіційним чином», – сказав Роберт Лі, старший аналітик Bloomberg Intelligence. «Але в ці часи обмежених витрат, якщо DeepSeek пропонує 90% функціональності ChatGPT, то споживачі можуть мати іншу думку щодо урядів».
Джерело: www.bloomberg.com
Ми збираємо новини з Reuters, BBC, Bloomberg та інших світових ЗМІ.
Коротко, факти, без фейків та зайвого галасу.
👉 Підписуйтесь у Telegram


